Implementing the Modern Stack at SAM Labs
SAM Labs’ data infrastructure was transformed after working with ELT Data Solutions. Learn more about the data journey at SAM Labs. Here we compare the current state of their infrastructure to what it was previously, and present the tools and vendors used to help transform their stack.
SAM Labs’ Stack Before ELT Data Solutions
This was the state of SAM Labs’ stack before working with ELT Data Solutions:
Hubspot (arguably not a part of a data stack but was being used a such)
Google Sheets
Microsoft Excel
Firebase (backend for SAM Studio application)
Google Analytics
Choosing Vendors
After reviewing and auditing over 15 vendors and data-as-a-service (DaaS) providers, we selected Snowflake as SAM Labs’ data warehouse and a combination of Matillion and Fivetran for data ingestion. This was due to some API restrictions Fivetran had at the time and the fact Matillion was significantly more affordable (and in some cases, free).
One issue we found with ingestion tools was a lack of ability to control the data schema. dbt solved for this and became our tool of choice for data modeling once data hit the warehouse. After data ingestion, storage, and transformation, the only part of the stack left was data consumption, also known as business intelligence or data visualization.
We opted for Tableau and Sigma Computing, where Tableau solved for embedded dashboards and Sigma solved for ad-hoc data exploration and data democratization.
The New Stack at SAM Labs

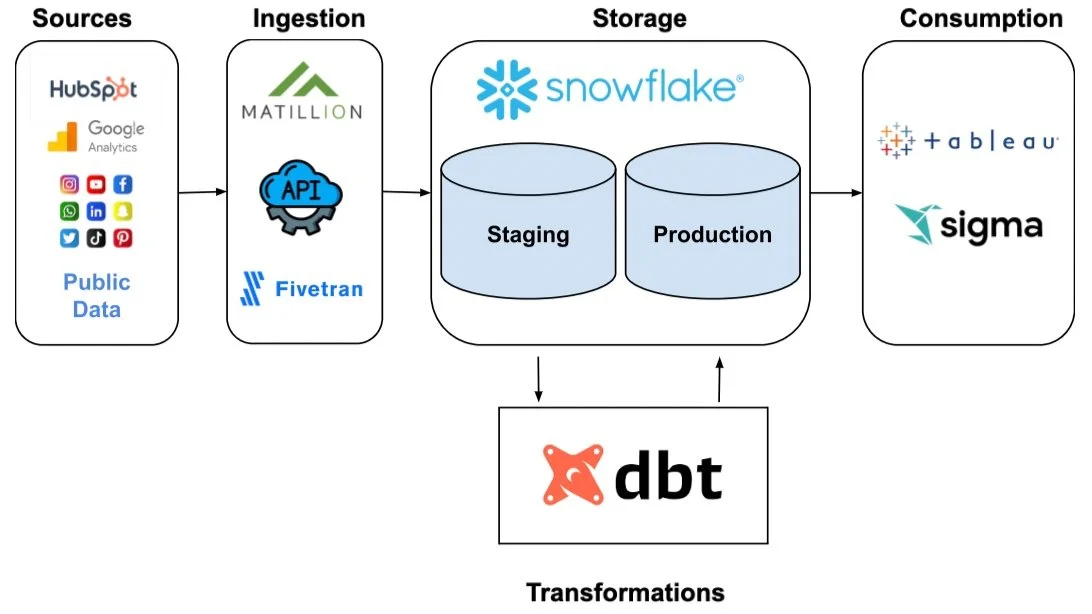
A diagram of the new stack built for SAM Labs (2021)
Sources
The majority of the source data was from Hubspot and Google Analytics, with public data from the National Center for Education Statistics (NCES). These data sources produced first-party data plus data from legacy integrations like Shopify and Netsuite. SAM Labs’ SaaS product, SAM Studio, also had an API and was used as a data source. Oftentimes, data was siloed by individual application and then exported or analyzed in an ad-hoc, non-reproducible fashion. Our goal was to create a single-source-of-truth for all things data and analytics.
Ingestion
Matillion was configured to load data into Snowflake every 24 hours for absolutely no cost. This came at the opportunity cost of a lack of integrations using Matillion’s free product offering, the Matillion Data Loader. An example of this opportunity cost was when the SAM Labs’ Marketing team wanted to analyze Hubspot workflow performance. This cannot be accomplished without a separate, independent API call using Python or Knime.
SAM Labs’ needed to call at least 10+ API endpoints to access data and analyze it. Due to the desire to limit costs (similar to why we implemented the free version of Matillion), this data was not loaded into our warehouse. To do so would increase SAM Labs’ monthly costs substantially, so instead data was called via API, transformed, then loaded into Snowflake.
Storage & Data Marts
The simplest section of the entire diagram. It’s best to approach the idea of “raw” vs “transformed” in terms of software development, where there is a staging and production environment. The staging environment is where raw data lands. It is not normalized and requires cleaning to be consumable. The production environment is where normalized, transformed data lands.
Data Marts are essentially team-specific databases within a data warehouse, where all data related to that team’s business needs and operations are stored in one place. Think of a data mart as a subset of a data warehouse with one departmental or business focus. At SAM Labs, we created data marts for Marketing, Product, Customer Success, Sales, and Business Operations. Hubspot had historically been used to house data for all these departments, so we needed to migrate from Hubspot to a proper cloud warehouse solution.
Transformations
As mentioned previously, dbt is our tool of choice for warehouse transformations. Envision all data entering a funnel and coming out on the other side, clean, normalized and in in columns and rows, and consumable. This is dbt. It helped us solve for personalized schemas. Schemas are the way data is represented in a series of tables within a datastore such as a data warehouse. Personalization matters when there is a need to customize data and apply business logic via data models. dbt, with a combination of API calls, gave SAM Labs the data they wanted from their applications that was not readily available from ingestion tools.
Consumption
The SAM Labs’ Marketing team consumed data through Hubspot and a weekly spreadsheet of metrics. Our goal was to shift SAM Labs to consuming data from a transformed data source that gives them reproducible, version-controlled insights. In order for data marts to be actionable, there must be a user interface on top of the data marts..
Sigma Computing fit the needs of SAM labs and met its vision of data democratization. Sigma, along with Tableau, were implemented to meet different use cases where Sigma solved for user access and a shared source of truth and Tableau solved for embedded analytics and dashboards. Eventually, the goal would be to migrate away from Tableau to Sigma Computing only.
Integrations and DataOps
Zapier and Segment were used for integrating and automating data operations like triggering Slack notifications, sending emails, and trigger reports. These can be helpful tools when there are business operations that need to take place but limitations on software engineering resources.