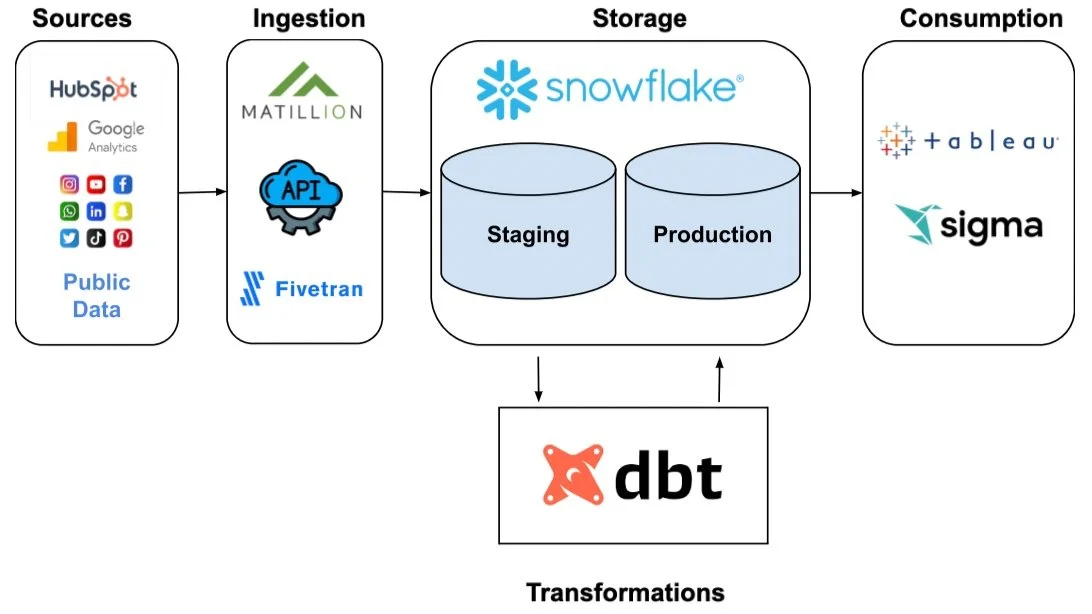
How to Ingest Data with Matillion at No Cost
We have built 30+ pipelines that load billions of rows of data….all for free. This tutorial will cover how to create new Matillion ingestion pipelines and manage pipelines.
Getting Started
Navigate to https://us.dataloader.matillion.com/ and log in with a Google account.

The SSO screen for Matillion
Under the menu click “Manage” then “Account”. You can manage OAuth which is a more sophisticated and established version of an API connection. In the screenshot below, we’ve authenticated Facebook Ads, Google Analytics, Hubspot, and Twitter.

The Manage menu for Matillion
Matillion requires a destination to send data to. This should be your data warehouse. You will need to insert account credentials like account (your server), username, and password. This establishes a JDBC driver connection.

Matillion can load data at different intervals. We opted for intervals of 12 and 24 hours. You can set alerts to be emailed to the administrator if a pipeline fails more than once. Each pipeline represents its own table, where the data from your source (Hubspot in this case) is deconstructed in Matillion then reconstructed in Snowflake.
Creating a Pipeline
For instance, let’s say we want to create a table called company_locations that combines eight location properties and the company ID property to create a single table of company locations. This uses Hubspot’s API to capture company_id as the primary key so this table can be joined or related to other tables based on a unique ID.
We have access to hundreds of different Hubspot table configurations that we can combine as we see fit. Let’s create the company_locations schema.

The Matillion Pipeline menu

Adding Hubspot as a data source
First, select the “Add Pipeline” button in the top right corner, then type “Hubspot” as the source and select “Next”. Lastly, identify the destination by selecting your data warehouse (Snowflake in our case). Name the table and select the OAuth method which you have saved in OAuth settings; this can be configured in the Account settings.

Selecting the destination and naming the table
After setting up the destination and initial data source, there is a “property menu” that allows the user to select the API objects, entities, or groups of properties to select columns from. Click the right arrow to add the object or group. For the company_locations table, we will select from the companies object.

Selecting Hubspot API properties
Select the individual properties (read columns) you want for the table by clicking the gear icon. If you know the exact name of the property, use the dropdown. Having a schema helps to remove some of the guesswork here. You can also click “Text Mode” then copy all column names to Notepad and use ctrl/cmd + f to find the desired properties. Once you have your properties click “Ok”.

Example of using “Text Mode” to identify desired fields

Custom schema for company locations
Set the staging and target configuration variables. This includes the warehouse, the database, and the schema in your warehouse (Snowflake in our case). You can name staging and production tables however you please. In this example we used the prefix stage_ and location_ for staging and production. This is because there are different location tables in production where there can be location_customers, location_companies, and so on.


Finally, set the interval for ingestion (12 or 24 hours), the email notification feature, then test the pipeline. In our example, everything works but we received a warning message around duplicate tables as this table already exists in the warehouse. Click “Create & Run” and you’ve got a new pipeline!

Example of testing pipeline and receiving an error message